Vantagens e desvantagens das máquinas de estados finitos: estruturas switch-case, ponteiros em C/C++ e tabelas de consulta (Parte II)
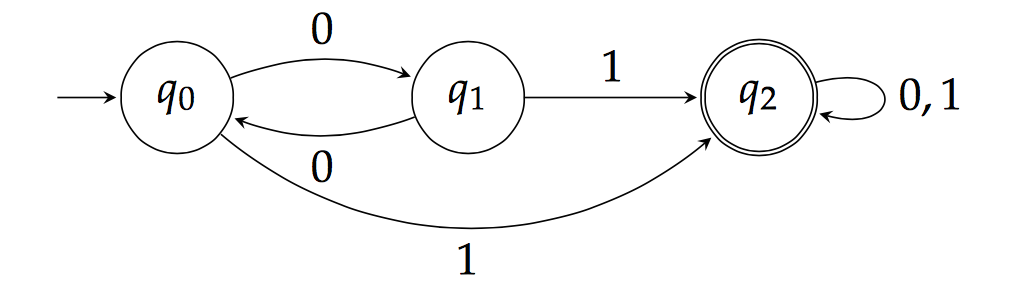
Esta é a segunda e última parte da nossa implementação de Máquina de Estados Finitos (MEF). Você pode consultar a primeira parte da série e aprender mais sobre Máquinas de Estados Finitos aqui .
Máquinas de Estados Finitos, ou MEFs, são simplesmente cálculos matemáticos de causas e eventos. Com base em estados, uma MEF computa uma série de eventos de acordo com o estado das entradas da máquina. Para um estado chamado LEITURA_DO_SENSOR , por exemplo, uma MEF poderia acionar um relé (também conhecido como evento de controle) ou enviar um alerta externo se a leitura de um sensor for maior que um valor limite. Os estados são o DNA da MEF – eles ditam o comportamento interno ou as interações com o ambiente, como aceitar entradas ou produzir saídas, que podem fazer com que um sistema mude de estado. É nossa função, como engenheiros de hardware, escolher os estados da MEF e os eventos de acionamento corretos para obter o comportamento desejado que atenda às necessidades do nosso projeto.
Na primeira parte deste tutorial sobre Máquinas de Estados Finitos (FSM), criamos uma FSM usando a implementação clássica de switch-case. Agora, vamos explorar a criação de uma FSM usando ponteiros em C/C++, o que permitirá desenvolver uma aplicação mais robusta com expectativas de manutenção de firmware mais simples.
NOTA : O código usado neste tutorial foi demonstrado no Arduino Day de 2018 em Bogotá por José Garcia, um dos Ubidots . Você pode encontrar os exemplos de código completos e as notas do palestrante aqui .
Desvantagens do Switch-Case:
Na primeira parte do nosso tutorial sobre Máquinas de Estados Finitos (MEF) , vimos as estruturas `switch-case` e como implementar uma rotina simples. Agora, vamos expandir essa ideia apresentando os "Ponteiros" e como aplicá-los para simplificar sua rotina de MEF.
Uma de switch-case é muito semelhante a uma if-else ; nosso firmware percorrerá cada caso, avaliando-os para verificar se a condição do caso de ativação foi atingida. Vejamos um exemplo de rotina abaixo:
switch(state) { case 1: /* cria algo para o estado 1 */ state = 2; break; case 2: /* cria algo para o estado 2 */ state = 3; break; case 3: /* cria algo para o estado 3 */ state = 1; break; default: /* cria algo por padrão */ state = 1; }
No código acima, você encontrará uma Máquina de Estados Finitos (MEF) simples com três estados. No loop infinito, o firmware irá para o primeiro caso, verificando se a variável de estado é igual a um. Se sim, ele executa sua rotina; caso contrário, ele prossegue para o caso 2, onde verifica o valor do estado novamente. Se o caso 2 não for satisfeito, a execução do código passará para o caso 3, e assim por diante, até que o estado seja alcançado ou os casos tenham sido esgotados.
Antes de analisarmos o código, vamos entender um pouco mais sobre algumas possíveis desvantagens das switch-case ou if-else para que possamos ver como melhorar o desenvolvimento do nosso firmware.
Vamos supor que a variável de estado inicial seja 3: nosso firmware terá que realizar 3 validações de valor diferentes. Isso pode não ser um problema para uma pequena máquina de estados finitos (FSM), mas imagine uma máquina de produção industrial típica com centenas ou milhares de estados. A rotina precisará realizar diversas verificações de valor desnecessárias, resultando, em última análise, em um uso ineficiente de recursos. Essa ineficiência se torna nossa primeira desvantagem – o microcontrolador tem recursos limitados e ficará sobrecarregado com rotinas ineficientes da FSM. Portanto, é nossa responsabilidade, como engenheiros, economizar o máximo possível de recursos computacionais no microcontrolador.
Agora imagine uma Máquina de Estados Finitos (MEF) com milhares de estados: se você for um desenvolvedor iniciante e precisar implementar uma alteração em um desses estados, terá que analisar milhares de linhas de código dentro da sua rotina principal (loop()). Essa rotina geralmente inclui muito código não relacionado à máquina em si, o que pode dificultar a depuração se toda a lógica da MEF estiver centralizada dentro do loop() principal.
Por fim, um código com milhares de if-else ou switch-case não é elegante nem legível para a maioria dos programadores de sistemas embarcados.
Ponteiros em C/C++
Agora, vejamos como podemos implementar uma Máquina de Estados Finitos (MEF) concisa usando ponteiros em C/C++. Um ponteiro, como o próprio nome sugere, aponta para algum lugar dentro do microcontrolador. Em C/C++, um ponteiro aponta para um endereço de memória com a intenção de recuperar informações. Um ponteiro é usado para obter o valor armazenado de uma variável durante a execução, sem a necessidade de conhecer o endereço de memória da própria variável. Usados corretamente, os ponteiros podem ser uma grande vantagem para a estrutura da sua rotina e para a simplicidade de futuras manutenções e edições.
- Exemplo de código de ponto:
int a = 1462; int myAddressPointer = &a; int myAddressValue = *myAddressPointer;
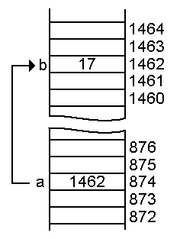
Vamos analisar o que acontece no código acima. A variável `myAddressPointer` aponta para o endereço de memória da variável `a` (1462) , enquanto a variável `myAddressValue` recupera o valor do endereço de memória apontado por `myAddressPointer`. Consequentemente, podemos esperar obter o valor 874 de `myAddressPointer` e 1462 de ` myAddressValue`. Por que isso é útil? Porque não armazenamos apenas valores na memória, mas também funções e comportamentos de métodos. Por exemplo, o espaço de memória 874 armazena o valor 1462, mas esse endereço de armazenamento também pode gerenciar funções para calcular a intensidade da corrente em kA. Ponteiros nos dão acesso a essa funcionalidade adicional e à usabilidade do endereço de memória sem a necessidade de declarar uma função em outra parte do código. Um ponteiro de função típico pode ser implementado como abaixo:
vazio (*funcPtr) (void);
Você consegue imaginar usar essa ferramenta em nossa Máquina de Estados Finitos (MEF)? Podemos criar um ponteiro dinâmico que aponta para as diferentes funções ou estados da nossa MEF em vez de uma variável. Se tivermos uma única variável que armazena um ponteiro que muda dinamicamente, podemos alterar os estados da MEF com base nas condições de entrada.
Tabelas de consulta
Vamos revisar outro conceito importante: tabelas de consulta, ou LUTs. As LUTs oferecem uma maneira ordenada de armazenar dados em estruturas básicas que armazenam valores predefinidos. Elas serão úteis para armazenarmos dados dentro dos valores de nossa Máquina de Estados Finitos (MEF).
A principal vantagem das LUTs é a seguinte: se declaradas estaticamente, seus valores podem ser acessados por meio de endereços de memória, o que é uma forma muito eficiente de acesso a valores em C/C++. Abaixo, você encontrará uma declaração típica para uma LUT de máquina de estados finitos (FSM):

void (*const state_table [MAX_STATES][MAX_EVENTS]) (void) = { action_s1_e1, action_s1_e2 }, /* procedimentos para o estado { action_s2_e1, action_s2_e2 }, /* procedimentos para o estado { action_s3_e1, action_s3_e2 } /* procedimentos para o estado };
É muita informação para assimilar, mas esses conceitos desempenham um papel fundamental na implementação da nossa nova e eficiente Máquina de Estados Finitos (MEF). Agora, vamos programá-la para que você possa ver como esse tipo de MEF pode crescer facilmente ao longo do tempo.
Nota: O código completo da máquina de estados finitos pode ser encontrado aqui – dividimos em 5 partes para simplificar.
Codificação
Vamos criar uma máquina de estados finitos (FSM) simples para implementar uma rotina de piscar um LED. Você poderá adaptar o exemplo às suas necessidades. A FSM terá dois estados: ledOn e ledOff, e o LED acenderá e apagará a cada segundo. Vamos começar!
/* CONFIGURAÇÃO DA MÁQUINA DE ESTADOS */ /* Estados válidos da máquina de estados */ typedef enum { LED_ON, LED_OFF, NUM_STATES } StateType; /* Estrutura da tabela da máquina de estados */ typedef struct { StateType State; // Cria o ponteiro de função void (*function)(void); } StateMachineType;
Na primeira parte, implementamos nossa LUT (Tabela de Consulta) para criar estados. Convenientemente, usamos o método enum() para atribuir os valores 0 e 1 aos nossos estados. O número máximo de estados também recebe o valor 2, o que faz sentido em nossa arquitetura de Máquina de Estados Finitos (FSM). Este typedef será rotulado como StatedType para que possamos nos referir a ele posteriormente em nosso código.
Em seguida, criamos uma estrutura para armazenar nossos estados. Também declaramos um ponteiro rotulado como função , que será nosso ponteiro de memória dinâmica para chamar os diferentes estados da máquina de estados finitos (FSM).
/* Declaração inicial de estado e funções da máquina de estados */ StateType SmState = LED_ON; void Sm_LED_ON(); void Sm_LED_OFF(); /* Tabela de consulta com estados e funções a serem executadas */ StateMachineType StateMachine[] = { {LED_ON, Sm_LED_ON}, {LED_OFF, Sm_LED_OFF} };
Aqui, criamos uma instância com o estado inicial LED_ON, declaramos nossos dois estados e, finalmente, criamos nossa LUT. As declarações de estado e o comportamento estão relacionados na LUT, então podemos acessar os valores facilmente por meio de índices int . Para acessar o método sm_LED_ON(), por exemplo, codificaremos algo como StateMachineInstance[0]; .
/* Rotinas de funções de estado personalizadas */ void Sm_LED_ON() { // Código da função personalizada digitalWrite(LED_BUILTIN, HIGH); delay(1000); // Mover para o próximo estado SmState = LED_OFF; } void Sm_LED_OFF() { // Código da função personalizada digitalWrite(LED_BUILTIN, LOW); delay(1000); // Mover para o próximo estado SmState = LED_ON; }
No código acima, a lógica dos nossos métodos está implementada e não inclui nada de especial além da atualização do número do estado ao final de cada função.
/* Rotina de mudança de estado da função principal */ void Sm_Run(void) { // Garante que o estado atual seja válido if (SmState < NUM_STATES) { (*StateMachine[SmState].function) (); } else { // Código de exceção de erro Serial.println("[ERRO] Estado inválido"); } }
A função Sm_Run() é o núcleo da nossa Máquina de Estados Finitos (MEF). Observe que usamos um ponteiro (*) para extrair a posição de memória da função da nossa Tabela de Consulta (LUT), visto que acessaremos dinamicamente uma posição de memória na LUT durante a execução. A função Sm_Run() sempre executará múltiplas instruções, também conhecidas como eventos da MEF, já armazenadas em um endereço de memória do microcontrolador.
/* FUNÇÕES PRINCIPAIS DO ARDUINO */ void setup() { // Coloque seu código de configuração aqui, para executar uma vez: pinMode(LED_BUILTIN, OUTPUT); } void loop() { // Coloque seu código principal aqui, para executar repetidamente: Sm_Run(); }
Nossas principais funções do Arduino agora são muito simples: o loop infinito está sempre em execução com a rotina de mudança de estado previamente definida. Esta função irá lidar com o evento para disparar e atualizar o estado real da máquina de estados finitos (FSM).
Conclusões
Nesta segunda parte da nossa série sobre Máquinas de Estados Finitos e Ponteiros em C/C++, analisamos as principais desvantagens das rotinas switch-case de Máquinas de Estados Finitos e identificamos os ponteiros como uma opção adequada e desejável para economizar memória e aumentar a funcionalidade do microcontrolador.
Em resumo, aqui estão algumas das vantagens e desvantagens de usar ponteiros em sua rotina de Máquina de Estados Finitos:
Vantagens:
- Para adicionar mais estados, basta declarar o novo método de transição e atualizar a tabela de pesquisa; a função principal permanecerá a mesma.
- Você não precisa executar todas as instruções if-else – o ponteiro permite que o firmware 'vá' para o conjunto desejado de instruções na memória do microcontrolador.
- Esta é uma forma concisa e profissional de implementar o FSM.
Desvantagens:
- Você precisa de mais memória estática para armazenar a tabela de consulta que guarda os eventos da máquina de estados finitos (FSM).
